SHINE-Mapping: Large-Scale 3D Mapping Using Sparse Hierarchical Implicit Neural Representations
Xingguang Zhong, Yue Pan, Jens Behley, Cyrill Stachniss
2023 IEEE International Conference on Robotics and Automation (ICRA)
10.1109/ICRA48891.2023.10160907

- Fist work aims construct maps based on point cloud as input
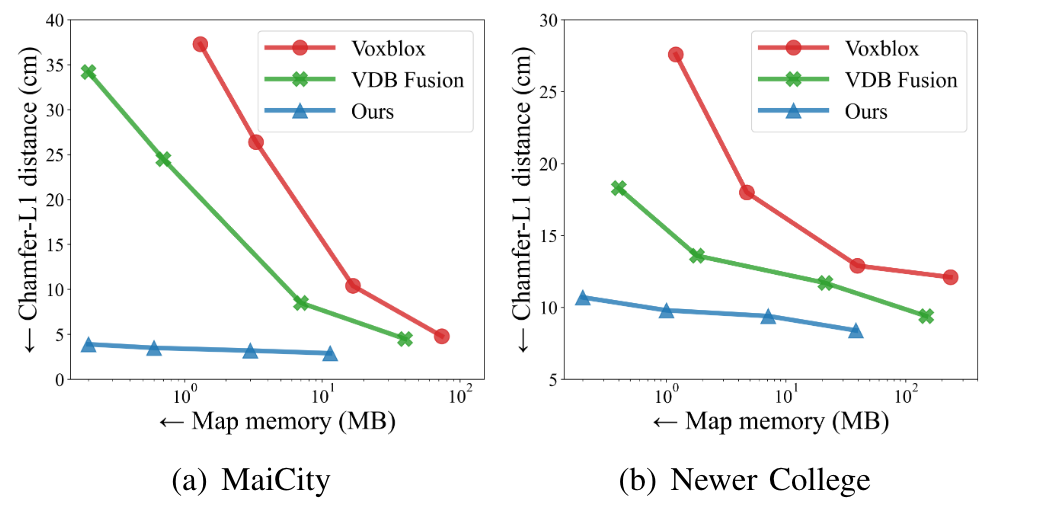
- Low memory cost, high speed, high performance
- Construct coodinate world based on the first frame
- Each Level has a Hash Table to store the feature vectors of node
- Point Sampling
- Incremental Mapping without forgetting
- Property of Lidar Scene : Sparse, noisy, get the true SDF is very difficult.
- Directly obtain training pairs by sampling points along the ray and directly use the signed distance from sampled point to the beam endpoint as the signed distance of the point and the underlying surface
- How to solve the accurancy problem?
- For SDF-based mapping, the regions of interst are the values close to zero as they define the surfaces.
- Sampling point closer to the endpoint should have a higher impact as the precise SDF value far from a surface has a very little impact.
- Insread of using
Loss, Using BCE(Binary Cross Entropy) Loss, The SDF value should be processed by a sigmoid function -
- Sampling Policy :
- Sampling
points in the fress space and points inside the truncation band around the surface
- Sampling
Eikonal Loss
- We can only obtain partial observations of the environment at each frame (
and ). During the incremental mapping, we use the data capture from Area to optimize feature , after the training converge, will have an accurate geometric representation of . However, if we move forward and use the data from frame to train and update , the network will only focus on reducing the loss generated in and does not care about the performance in anymore. This may lead to a decline in the reconstruction accuracy in . Same problem happens from to
Update the importance weright as the sensitivity of the loss of previous data to a parameter change suggested in previous incremental learning research:
!qualitative_mai_v3.png
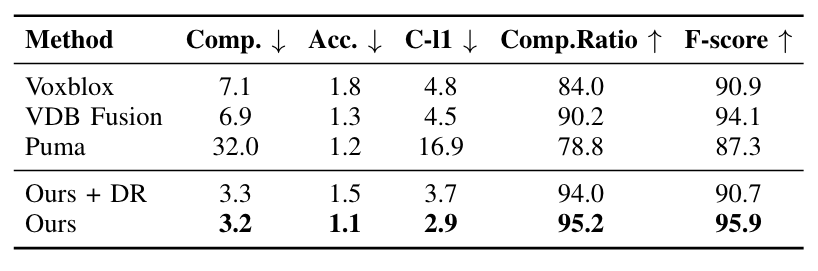
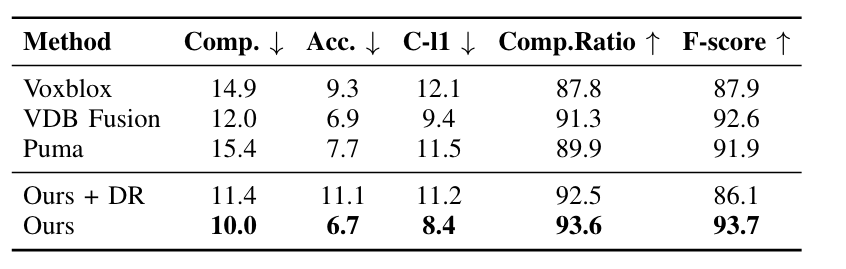
A comparison of different methods on the MaiCity dataset. The first row shows the reconstructed mesh and a tree is highlighted in the black box. The second row shows the error map of the reconstruction overlaid on the ground truth mesh, where the blue to red colormap indicates the signed reconstruction error from -5 cm to +5 cm. (From left to right: Shine,(TSDF-based Method)Voxblox,(TSDF-based)VDF Fusion, (Possion-based Surface Reconstruction)Puma, Shine+DR(With Diffential Rendering method))